GenDCデータの解析
このチュートリアルでは、GenDCセパレータライブラリの使い方を学びます。 デバイスのデータ形式がGenDC以外の場合(一般的なカメラが画像を取得する場合)、次のチュートリアルページ非GenDCバイナリデータの解析を参照してください。
デバイスがGenDC形式でない場合は、9つのうち6つが有効なコンポーネントかつ、4つの異なるセンサーデータを含むサンプルGenDCをダウンロードし、本チュートリアルで利用することができます。
Prerequisite
- GenDC Separator
- OpenCV
- numpy
pip3 install -U pip
pip3 install opencv-python
pip3 install numpy
pip3 install gendc-python==0.2.8
- GenDCデータ(前のチュートリアルで取得したもの、またはこのページからダウンロードしたサンプル)
チュートリアル
前のチュートリアルでは、GenDCデータをバイナリファイルに保存する方法を学びました。今回はそのデータをロードし、コンテナを解析して、センサーの記述子からいくつかの情報を取得します。
このチュートリアルで使用するGenDCには少なくとも1つの画像データコンポーネントが含まれていると仮定します。前のチュートリアルで保存したデータがない場合は、このページからサンプルデータをダウンロードしてください。
GenDC
GenDC(Generic Data Container)は、EMVA(European Machine Vision Association)によって定義されています。その名の通り、データの次元、メタデータ、画像シーケンス・バーストかどうかに関わらず、カメラデバイスが定義するあらゆる種類のデータを含むことができます。
フォーマットルールは公式ドキュメントで定義されていますが、GenDCセパレータはコンテナ全体を簡単に解析するのに役立ちます。
GenDCの概要を学びたい場合は、GenDCの概念と大まかな構造を説明するこのページをチェックしてください。
バイナリファイルの探索
前のチュートリアルで保存したバイナリファイルを使用する場合、ディレクトリ名はtutorial_save_gendc_XXXXXXXXXXXXXXで、バイナリファイルのプレフィックスはgendc0-です。
directory_name = "tutorial_save_gendc_XXXXXXXXXXXXXX"
prefix = "gendc0-"
このチュートリアルの最後に提供される完全なコードは、コマンドラインオプションがついています。
-d tutorial_save_gendc_XXXXXXXXXXXXXXまたは--directory tutorial_save_gendc_XXXXXXXXXXXXXXオプションを設定してチュートリアルプログラムを実行すると、directory_nameが自動的に設定されます。
また、チュートリアルページの上部で提供されているサンプルデータoutput.binを使用する場合は、-uまたは--use-dummy-dataオプションを追加するだけで、ダウンロードされたoutput.binをプログラムが検索するようになります。
以下のスニペットでは、指定されたプレフィックスで始まるすべてのバイナリファイルをディレクトリから取得し、それらを録画された順番に並び替えています。
bin_files = [f for f in os.listdir(directory_name) if f.startswith(prefix) and f.endswith(".bin")]
bin_files = sorted(bin_files, key=lambda s: int(s.split('-')[-1].split('.')[0]))
これでbin_files内のすべての順序付けられたバイナリファイルをforループで処理する準備が整いました。
for bf in bin_files:
バイナリファイルを開いて読み込む
forループ内のバイナリファイルはbfで表されています。このバイナリファイルをifsで開きます。
bin_file = os.path.join(directory_name, bf)
with open(bin_file, mode='rb') as ifs:
filecontent = ifs.read()
バイナリファイルの解析
はじめに、GenDCセパレータモジュールをimportしてください。
from gendc_python.gendc_separator import descriptor as gendc
データから以下のようにしてGenDC ContainerHeaderオブジェクトを作成できます。GenDCの用語(Container、Component、Partなど)について学ぶには、このページをチェックしてください。
gendc_container = gendc.Container(filecontent[cursor:])
もしこのオブジェクトがエラーを返した場合、データにGenDC署名が含まれていない、つまりGenDC形式でない可能性があります。
このオブジェクトには、GenDC Descriptorに書かれたすべての情報が含まれているので、Descriptorのサイズとデータのサイズを取得できます。
# get GenDC container information
descriptor_size = gendc_container.get_descriptor_size()
container_data_size = gendc_container.get_data_size()
コンテナ全体のサイズは、このDescriptorSizeとDataSizeの合計です。元のデータのオフセットとして合計を追加することで次のコンテナ情報をロードすることができます。
next_gendc_container= gendc.Container(filecontent[cursor + descriptor_size + container_data_size:])
このチュートリアルでは、どのComponentに画像センサデータが含まれているかを検出し、センサデータの情報(チャンネル数、データの次元、バイト深度など)を取得し、最終的にOpenCVで画像を表示します。
まず、get_1st_component_idx_by_typeid()を使用して最初の有効な画像データComponentを見つける必要があります。これにより、パラメータと一致するデータタイプの最初の有効なデータComponentのインデックスが返されます。-1を返す場合、有効なデータがセンサー側に設定されていないことを意味します。
ここに、GenICamによって定義されたいくつかのデータタイプがあります。
| データタイプキー | データタイプID値 |
|---|---|
| 未定義 | 0 |
| 強度 | 1 |
| 赤外線 | 2 |
| 紫外線 | 3 |
| 距離 | 4 |
| ... | ... |
| メタデータ | 0x8001 |
参照: GenICam標準機能命名規約の4.13ComponentIDValue
今回は画像(すなわち輝度)データを取得するために、データタイプID値として1を使用します。
# get first available component
image_component_idx = gendc_container.get_1st_component_idx_by_typeid(GDC_INTENSITY)
これで、画像データを含むComponentのヘッダー情報にアクセスできます。
image_component = gendc_container.get_component_by_index(image_component_idx)
part_count = image_component.get_part_count()
Componentには1つ以上のPartがあります。forループを使用してそれらを反復処理できます。画像ComponentのPartの数は通常、カラーチャンネルの数です。例えば、モノクロ空間画像では1、一般的なRGBなどのカラーピクセルフォーマットでは3です。
part_count = image_component.get_part_count()
for part_id in range(part_count):
part = image_component.get_part_by_index(part_id)
part_data_size =part.get_data_size()
現在画像データ全体のサイズはpart_data_sizeで判明していますが、プレビュー画像を表示するためは2Dにしなければならないので、次の情報を確認する作業が必要です。
- 幅
- 高さ
- カラーチャンネル
- バイト深度
get_dimension は、幅と高さを含むベクターを返します。
dimension = part.get_dimension()
バイト深度を決定するには、データの総サイズと上記の取得された次元値から計算できます。
w_h_c = part_count
for d in dimension:
w_h_c *= d
byte_depth = int(part_data_size / w_h_c)
これで、データを1D配列imagedataから画像形式のcv::Matimgにmemcpyでコピーして表示することができます。
width = dimension[0]
height = dimension[1]
if byte_depth == 1:
image = np.frombuffer(part.get_data(), dtype=np.uint8).reshape((height, width))
elif byte_depth == 2:
image = np.frombuffer(part.get_data(), dtype=np.uint16).reshape((height, width))
cv2.imshow("First available image component", image)
cv2.waitKey(1)
このページの上部で提供されているサンプルデータを使用すると、次のような画像が表示されます。
 .
.
サンプルデータの例
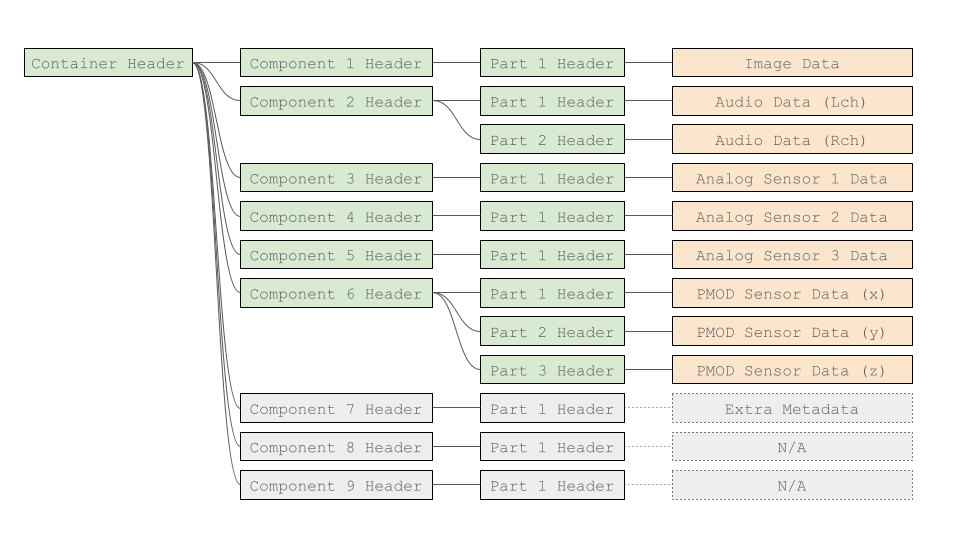
前のセクションでは、GenDCセパレータAPIを使用してGenDCデータを解析する一般的なアイデアを学びました。今度は、このページの上部(またはこちら)で提供されているサンプルデータを使用して、いくつかの非画像データを処理できます。
 。
。
画像センサデータで行ったように、1. チャンネル数 2. データの次元 3. データのバイト深度を取得することでユーザアプリケーションで使用可能になります。Pythonのチュートリアルでは視覚化のためのコードも提供しています Visualize GenDC data。
サンプルデータに入っているすべての非画像データのデータタイプはメタデータであるため、TypeIdで目的のComponentを見つけることはできません。各コンポーネントにアクセスするためには別の情報が必要です。
通常、各Componentにはデータを検出するための一意のSourceIdがあります。今回は、ターゲットComponentを探すためにget_1st_component_idx_by_sourceidを使用します。
| コンポーネントインデックス | センサータイプ | 有効性 | SourceId | TypeId |
|---|---|---|---|---|
| 0 | 画像 | 有効 | 0x1001 | 1 (Intensity) |
| 1 | 音声 | 有効 | 0x2001 | 0x8001 (Metadata) |
| 2 | アナログ1 | 有効 | 0x3001 | 0x8001 (Metadata) |
| 3 | アナログ2 | 有効 | 0x3002 | 0x8001 (Metadata) |
| 4 | アナログ3 | 有効 | 0x3003 | 0x8001 (Metadata) |
| 5 | PMOD | 有効 | 0x4001 | 0x8001 (Metadata) |
| 6 | 追加 | 無効 | 0x0001 | 0x8001 (Metadata) |
| 7 | 該当なし | 無効 | 0x5001 | 0x8001 (Metadata) |
| 8 | 該当なし | 無効 | 0x6001 | 0x8001 (Metadata) |
オーディオデータの取得
目的のComponentのインデックスがわかると、画像Componentと同様にComponentHeaderオブジェクトを作成できます。
component_index = gendc_container.get_1st_component_idx_by_sourceid(0x2001)
audio_component = gendc_container.get_component_by_index(component_index)
このContainerには2つのパーツがあり、それぞれにオーディオデータの左チャンネルと右チャンネルが含まれています。
part_count = audio_component.get_part_count()
一部のオーディオセンサーは、LchとRchを交互に同じPartに格納するインターリーブオーディオを使用します。
この場合、audio_component.get_part_count()は1を返しますが、データを使用するには2次元に再構築する必要があります。
画像Componentと同様に、各Partのデータサイズと次元を確認します。
for j in range(part_count):
part = audio_component.get_part_by_index(j)
part_data_size =part.get_data_size()
dimension = part.get_dimension()
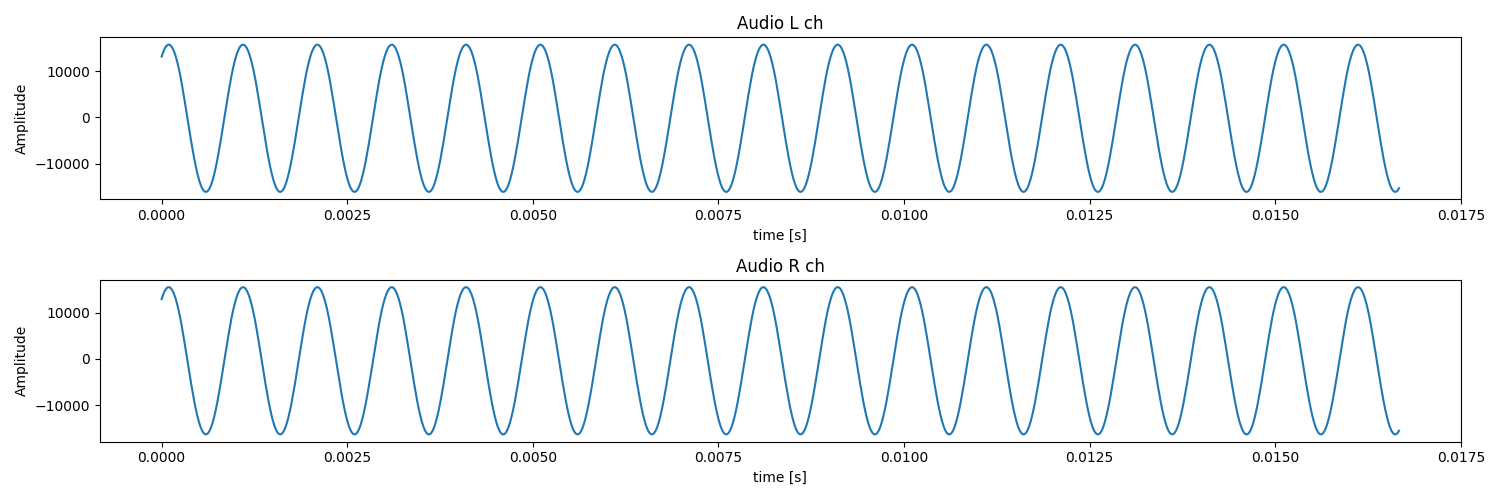
ここで、dimensionは{800}です。通常、GenDCの画像Componentは1フレームのデータを格納しますが、他のセンサーデータはその画像データを取得するのにかかる時間内に取得されたサンプルを格納します。例えば、画像が60fpsで取得されている場合、1/60秒以内に取得されたサンプルのみが格納されます。このオーディオデータは48kHzでサンプリングされ、1/60秒内に800サンプルが取得されるため、次元は800になります。
このオーディオデータの型を知るためには、データのサイズと次元で計算できるバイト深度が必要です。
byte_depth = int(part_data_size / w_h_c)
part_data_sizeが1600であるため、バイト深度は2であり、型はint16_tとなります。
このデータを前述のPythonチュートリアルコードで視覚化すると、以下のプロットが確認できます。
 。
。
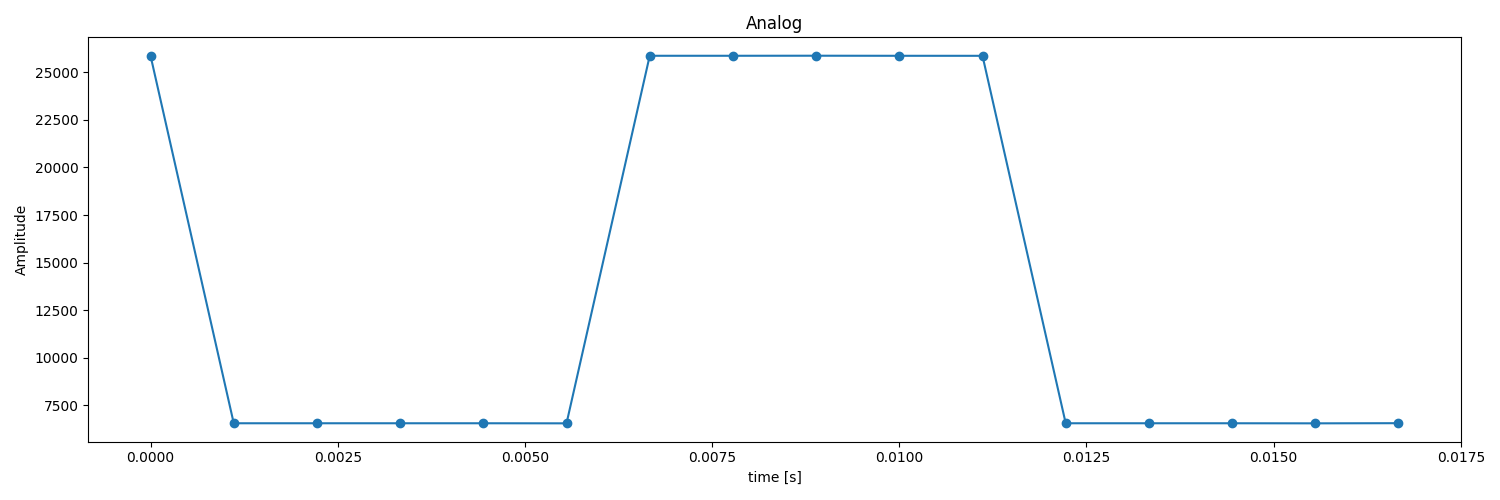
アナログデータの取得
このGenDCデータには、識別子0x3001、0x3002、および0x3003を持つ3つのアナログセンサがあります。get_1st_component_idx_by_sourceid()を使用してComponentのインデックスを見つけることができます。
component_index = gendc_container.get_1st_component_idx_by_sourceid(0x3001)
analog_component = gendc_container.get_component_by_index(component_index)
各アナログセンサのComponentには1つのPartが含まれており、これはget_part_count()で確認できます。
part_count = analog_component.get_part_count()
データサイズ、次元(サンプル数)、バイト深度を知るためにPartを取得できます。
for j in range(part_count):
part = analog_component.get_part_by_index(j)
part_data_size =part.get_data_size()
dimension = part.get_dimension()
このデータを前述のPythonチュートリアルコードで視覚化すると、以下のプロットが確認できます。
 。
。
PMODデータの取得
このGenDCデータには1つのPMOD加速度センサがあり、これは加速度計でx、y、zの座標情報を記録します。したがって、Partsの数は3です。
component_index = gendc_container.get_1st_component_idx_by_sourceid(0x4001)
pmog_component = gendc_container.get_component_by_index(component_index)
part_count = pmog_component.get_part_count()
一部の加速度センサーはインターリーブ構造を使用し、X、Y、Zの座標を交互に同じPartに格納します。
この場合、pmog_component.get_part_count()は1を返しますが、データを使用するには3次元(または1つのダミーチャンネルを追加して4次元)に再構築する必要があります。
データサイズ、次元(サンプル数)、バイト深度を知るためにPartを取得できます。
for j in range(part_count):
part = pmog_component.get_part_by_index(j)
part_data_size =part.get_data_size()
dimension = part.get_dimension()
各Partにはそれぞれx、y、zのデータが含まれており、前述のPythonチュートリアルコードで視覚化すると、以下のプロットが確認できます。
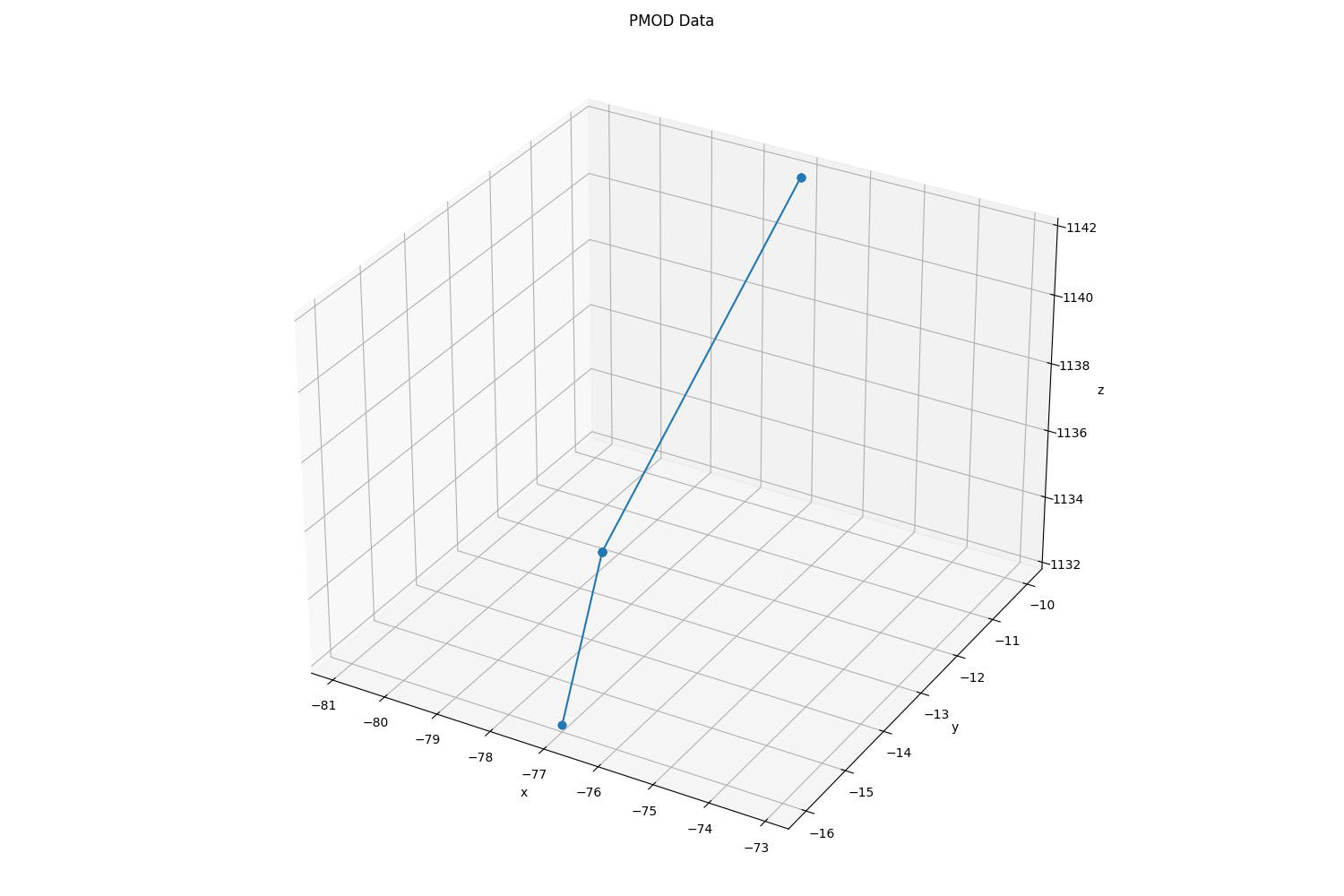 。
。
Typespecificの使用
GenDCのTypeSpecificフィールドに格納されたデバイス固有のデータにアクセスしたいときはget_typespecific_by_index()を使う必要があります。
例えば、以下のGenDCデータには、8バイトのTypeSpecific3の下位4バイトにframecountデータが含まれています。
TypeSpecificはN=1、2、3...から始まり、インデックスは0、1、2...なので、TypeSpecific3のインデックスは2です。
typespecific3 = part.get_typespecific_by_index(2)
print("Framecount: ", int.from_bytes(typespecific3.to_bytes(8, 'little')[0:4], "little"))
Complete code
このチュートリアルで使用される完全なコードはこちらです。